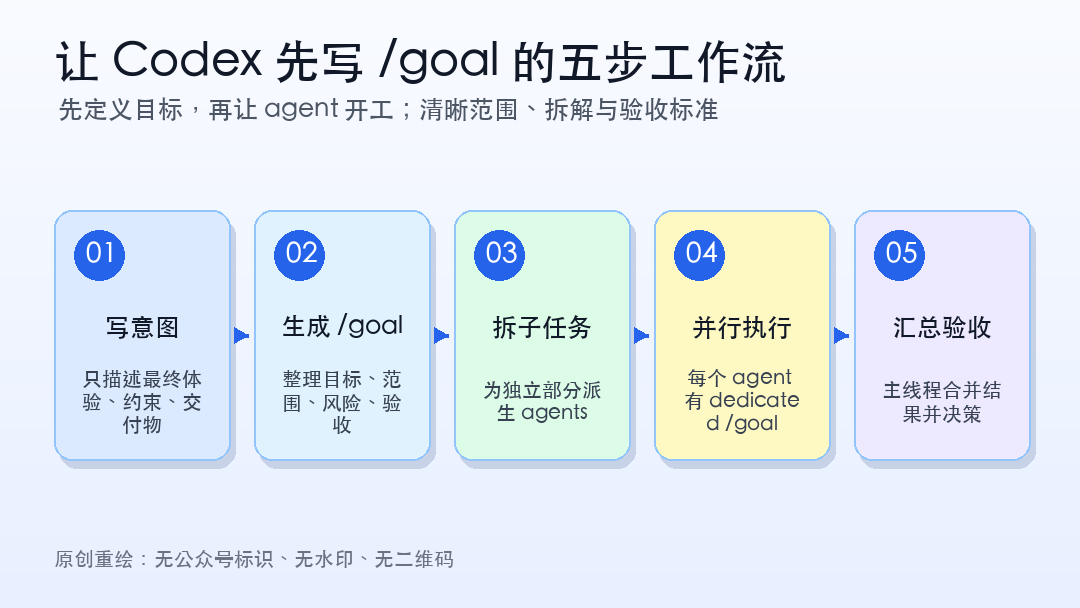
让 Codex 先写 /goal:复杂任务更稳的五步工作流

很多人用 AI 写代码,真正卡住的地方往往不是模型不够强,而是任务交代得太散。
一句“帮我做完这个功能”丢出去,后面就开始反复补充、纠偏、救火。短任务还行,任务一长,模型很容易只抓住最显眼的部分,后面的约束、边界和验收标准慢慢就散了。
这篇原文讲的 /goal 方法,本质不是偷懒少写几个字,而是让 Codex 在开工前,先把“目标、范围、拆解、风险、验收”整理成一份可以执行的工作协议。
换句话说:不要急着让 Codex 干活,先让它写清楚自己准备怎么干活。
/goal 真正解决的不是 prompt,而是任务定义
过去我们写 prompt,经常把需求描述、执行步骤、注意事项和验收标准揉在一段话里。简单问题没什么影响,但复杂任务里,这种写法很容易让模型跑偏。
更稳的做法,是先让 Codex 给自己写一个新的 /goal。
这个 goal 要把你的意图改写成明确目标,并列出范围、约束、子任务、风险和验收标准。人负责给方向,agent 先把方向翻译成任务。
这和普通 prompt 的差别很大。
普通 prompt 像是“我给你一串指令,你照着做”。而 /goal 更像一次小型项目会:你说想要什么,Codex 先把任务定义、拆解方式、子任务边界和验收标准讲清楚,然后再开始执行。
所以,/goal 不是魔法咒语,它更像 agent 的工作协议。
真正有价值的地方,也不是“让 AI 自己决定一切”,而是让 AI 先把人的模糊意图,整理成可执行、可检查、可更新的计划。
五步工作流:先定义目标,再让 agent 开工
这套方法可以压缩成五步。
第一步,只写意图,不要急着写完整计划。
比如你想做一个 Three.js 第一视角过山车 demo,不需要一上来就把所有实现细节写死。先说清楚最终体验、约束和交付物就够了:循环轨道、下坠、倾斜转弯、倒挂、速度感、地形、天空盒、音效,以及最终交付一个单 HTML 文件。
这一步的重点,是让你先描述“想要什么”,而不是替 agent 过早规定“每一步怎么做”。
第二步,要求 Codex 先给自己写 goal。
这是核心动作。不要直接说“开始做”,而是让它先把任务转换成可执行目标。
可以直接这样写:
For this task, write yourself a new goal first. Turn my request into a concrete objective with scope, constraints, subtasks, and acceptance criteria. Then execute against that goal.
中文也可以更直白:
先不要急着实现。请先为你自己写一个新的 /goal:把我的需求改写成清晰目标,列出范围、约束、子任务、风险和验收标准。确认这个 goal 后,再按它执行。
这一步看起来慢,其实是在减少后面的返工。
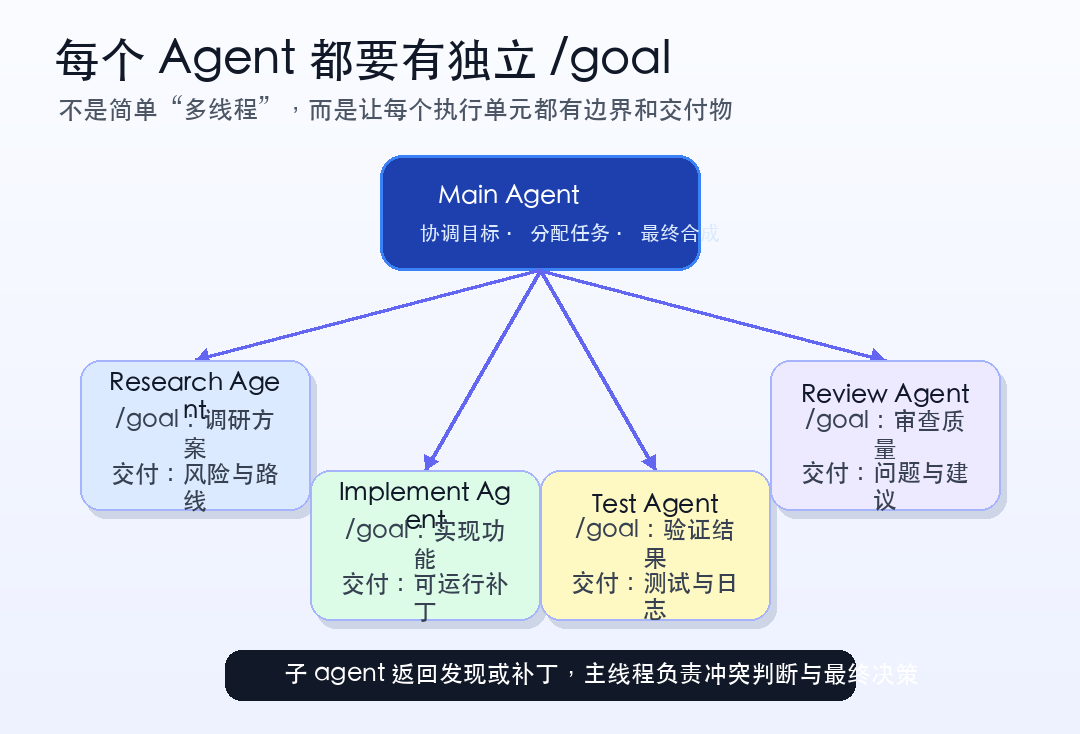
第三步,如果任务够大,让它派生子 agent。
长任务往往不是一个线程能顺滑做完的。研究、实现、测试、审查,可以拆成相互独立的部分。
关键不是简单说“并行处理”,而是要求每个子 agent 都带着自己的 dedicated /goal 出发,明确自己负责什么、交付什么、不要碰什么。
可以补上这句:
If this benefits from parallel work, spawn agents for independent pieces. Give each agent its own dedicated /goal, make their deliverables explicit, and synthesize the results when they return.
这样拆出去的不是一堆松散任务,而是一组边界清楚的小工作单元。
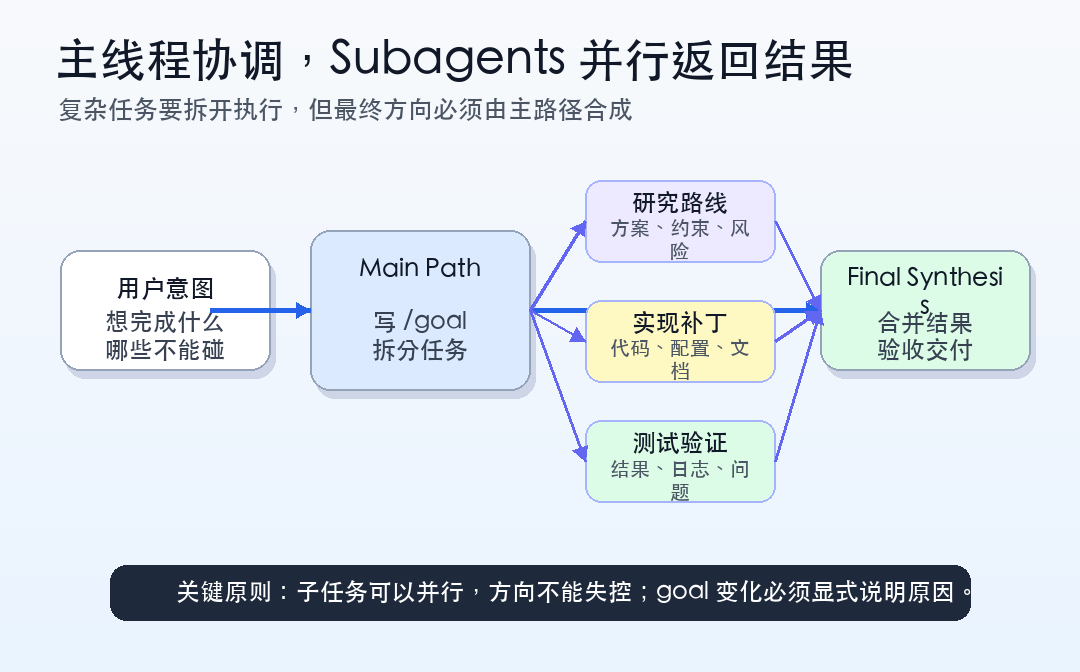
第四步,主线程负责汇总,而不是让子 agent 抢方向。
并行 agent 最大的坑,是每个子任务看起来都做了,但最后拼不起来。
所以主线程必须保留“总编”角色:收集子结果,判断冲突,合并方案,决定下一步。子 agent 负责研究、补丁、测试和发现,主线程负责最终取舍。
这句话可以直接加进 prompt:
Keep the main path responsible for coordination. Subagents should return findings or patches, but the main agent must synthesize and make final decisions.
第五步,把 goal 当成可更新对象。
长任务最怕目标漂移。好的做法不是禁止修改目标,而是要求任何修改都必须显式说明。
If the goal needs to change, update it explicitly and explain what changed before continuing.
这样一来,agent 如果发现原目标不完整,可以调整;但它不能悄悄换题。你能看到目标为什么变、变成了什么、后续会按什么标准验收。
哪些任务适合,哪些任务别折腾
这套方法特别适合三类任务。
第一类是长代码任务。只要任务会持续超过 20 分钟,或者你预感中途要补充需求,就值得先让 Codex 写 goal。
第二类是多模块改造。比如前端、后端、测试、文档都要动,最好把研究、实现和验证拆开,让不同 agent 各自带目标工作。
第三类是探索型项目。你并不完全确定技术路线时,先让 agent 把范围、风险和验收标准整理出来,会比直接开写更稳。
不适合的场景也很明确:小修小补、单文件改一行、你已经有非常精确的实现方案。这种时候再写 /goal,反而会多一层仪式感。
我的判断是:任务越长、越复杂,/goal 的收益越明显;任务越短、越确定,它就越容易变成流程负担。
一段可以直接复制的模板
以后做复杂代码任务,可以把第一段换成你的真实需求,后面这段基本保留:
1 | I want to accomplish the following task: |
如果是代码任务,建议再补三条:
1 | Read the existing codebase first and follow local patterns. |
这三条很朴素,但很管用。它们把 agent 从“自由发挥”拉回到工程现场:先看项目现状,只做相关修改,最后用测试或检查验证结果。
最后,人的角色不是消失,而是前移
/goal 这类用法会让 agent 更像一个能维护上下文的合作者,但它不会自动替你完成产品判断。
你仍然要负责意图:要做什么,为什么做,哪些东西不能碰,结果怎么算完成。
Codex 负责把这些意图整理成工作目标,再把目标拆给合适的执行单元。人的角色不是从流程里消失,而是从“逐字写指令”变成“定义方向和验收”。
可以把这套方法记成一句话:不要只让 Codex 干活,先让它写清楚自己要怎么干活。